💡 문제
모음사전 (https://school.programmers.co.kr/learn/courses/30/lessons/84512)
자세한 문제 설명과 입출력 예는 링크를 참고해주세요.
📝 선행 개념
완전탐색 (Brute Force):
- 가능한 모든 경우의 수를 탐색하여 해답을 찾는 방법입니다. 이 문제에서는 'A', 'E', 'I', 'O', 'U'라는 5개의 문자로 만들 수 있는 길이 1부터 5까지의 모든 단어를 생성해야 합니다. 이를 통해 사전의 모든 단어를 구할 수 있습니다.
재귀 함수 (Recursive Function):
- 함수가 자기 자신을 호출하여 문제를 해결하는 방법입니다. 이 문제에서는 재귀 함수를 사용하여 길이 1부터 5까지의 모든 단어를 생성합니다. 예를 들어, 현재 단어가 "A"일 때, 다음 단계에서는 "AA", "AE", "AI", "AO", "AU"와 같은 단어들을 생성합니다.
정렬
정렬은 문자열을 사전에서의 순서대로 정렬하는 방법입니다. 이 문제에서는 리스트에 저장된 모든 단어를 사전순으로 정렬하여 주어진 단어의 위치를 찾습니다. Java에서는 Collections.sort() 메서드를 사용하여 리스트를 쉽게 정렬할 수 있습니다.
자료구조-리스트
리스트는 순서가 있는 데이터를 저장하는 자료구조입니다. 이 문제에서는 생성된 모든 단어를 리스트에 저장합니다. 리스트를 사용하면 데이터를 순서대로 저장하고, 정렬한 후 인덱스를 쉽게 찾을 수 있습니다.
🤓 문제 풀이
🔨 문제 설명
주어진 단어가 모음('A', 'E', 'I', 'O', 'U')만을 사용하여 만들 수 있는 길이 5 이하의 모든 단어가 수록되어 있습니다. 사전에서 첫 번째 단어는 "A"이고, 그 다음은 "AA"이며, 마지막 단어는 "UUUUU"입니다. 모든 단어가 수록된 사전에서 단어 하나 몇 번째 단어인지 구하는 문제입니다.
🔨 접근 방법
사전은 모든 가능한 단어들을 사전순으로 정렬한 리스트입니다. 이 리스트에서 주어진 단어의 인덱스를 찾는 것이 목표입니다.
사전을 만들지 않고도 특정 단어의 순서를 구하기 위해 각 자리의 위치를 계산해줄 수 있습니다. 사전에서의 각 단어의 순서는 다음 규칙에 따라 정해집니다:
- 사전의 각 자리마다 5개의 문자가 있습니다.
- 첫 번째 자리의 경우 5^4 개의 단어가 존재합니다.
- 두 번째 자리의 경우 5^3 개의 단어가 존재합니다.
- 세 번째 자리의 경우 5^2 개의 단어가 존재합니다.
- 네 번째 자리의 경우 5^1 개의 단어가 존재합니다.
- 다섯 번째 자리의 경우 5^0 개의 단어가 존재합니다.
이 정보를 이용하여 주어진 단어가 몇 번째 위치에 있는지 계산할 수 있습니다.
또는 완전탐색을 통해 문제를 해결하기 위해 모든 가능한 단어를 생성한 후, 이를 사전순으로 정렬하여 주어진 단어의 위치를 찾습니다. 자료구조로는 리스트를 사용하여 모든 단어를 저장하고, 사전순 정렬을 통해 단어의 인덱스를 찾습니다.
🔨 문제 풀이 과정
- 각 자리의 문자에 해당하는 값들을 준비합니다.
- 각 자리의 위치를 곱하여 해당 단어가 몇 번째에 위치하는지 계산합니다.
- 결과 값을 반환합니다.
- 단어가 "AAAAE"인 경우:
- 첫 번째 자리: A (0) * 5^4
- 두 번째 자리: A (0) * 5^3
- 세 번째 자리: A (0) * 5^2
- 네 번째 자리: A (0) * 5^1
- 다섯 번째 자리: E (4) * 5^0
따라서 각 자리별 계산을 더하면 단어의 위치를 파악해준다.
- 가능한 모든 단어 생성: 길이 1부터 5까지의 모든 단어를 생성합니다. 이를 위해 재귀 함수를 사용합니다.
- 리스트에 저장: 생성된 단어를 리스트에 저장합니다.
- 사전순 정렬: 리스트를 사전순으로 정렬합니다.
- 단어의 위치 찾기: 정렬된 리스트에서 주어진 단어의 인덱스를 반환합니다.
🔨 구현코드
1-계산
class Solution {
public int solution(String word) {
// 모음 배열
char[] vowels = {'A', 'E', 'I', 'O', 'U'};
// 단어의 길이
int len = word.length();
// 위치를 저장할 변수
int position = 0;
// 각 자리마다 계산된 값을 저장할 변수
int[] base = {781, 156, 31, 6, 1};
for (int i = 0; i < len; i++) {
// 현재 문자가 모음 배열에서 몇 번째인지 계산
for (int j = 0; j < vowels.length; j++) {
if (word.charAt(i) == vowels[j]) {
position += j * base[i];
break;
}
}
// 현재 자리수에 해당하는 값 추가
position += 1;
}
return position;
}
}
2-완전탐색
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
class Solution {
// 가능한 모든 단어들을 저장할 리스트
private List<String> words = new ArrayList<>();
// 모음 배열
private char[] vowels = {'A', 'E', 'I', 'O', 'U'};
// 모든 단어를 생성하는 재귀 함수
private void generateWords(String current, int depth) {
// 단어의 최대 길이가 5이므로, 5를 넘으면 종료
// 길이가 5보다 크면 더 이상 추가하지 않음
if (depth > 5) {
return;
}
// 현재 단어를 리스트에 추가
if (!current.equals("")) {
words.add(current);
}
// 각 모음을 추가하여 재귀 호출
for (char vowel : vowels) {
generateWords(current + vowel, depth + 1);
}
}
public int solution(String word) {
// 모든 가능한 단어 생성
generateWords("", 0);
// 사전순으로 정렬
Collections.sort(words);
// 주어진 단어의 위치 반환 (1-based index 이므로 +1)
return words.indexOf(word) + 1;
}
}📚 풀이 보완
코드 설명
1.코드
- vowels 배열: 모음을 정의합니다.
- base 배열: 각 자리별로 몇 개의 단어가 존재하는지 저장합니다.
- 각 자리별로 반복하면서, 현재 문자가 모음 배열에서 몇 번째인지 찾고, 해당 값을 base 배열과 곱하여 position에 더해줍니다.
- 마지막으로 각 자리마다 단어 수를 더해줍니다.
2.코드
- words 리스트는 가능한 모든 단어를 저장합니다.
- vowels 배열은 사용할 모음을 정의합니다.
- generateWords 메서드는 현재 단어에 각 모음을 추가하여 재귀적으로 모든 단어를 생성합니다.
- 단어의 길이가 5를 넘으면 종료합니다.
- 현재 단어를 리스트에 추가합니다.
- 각 모음을 추가하여 재귀 호출합니다.
- 생성된 단어들을 Collections.sort() 메서드를 사용하여 사전순으로 정렬합니다.
- words.indexOf(word)를 사용하여 주어진 단어의 인덱스를 찾아 반환합니다.
- solution 메서드: 주어진 단어의 위치를 찾습니다.
- 모든 가능한 단어를 생성합니다.
- 단어들을 사전순으로 정렬합니다.
- 주어진 단어의 위치를 반환합니다. (1-based index 이므로 +1을 합니다)
이 방법은 완전탐색을 사용하여 모든 가능한 단어를 생성하고 주어진 단어의 위치를 찾는 방식입니다. 하지만, 이 방식은 비효율적일 수 있으며, 이전에 설명한 계산을 통해 위치를 찾는 방법이 훨씬 더 효율적입니다.
📍 Plus+
시간 복잡도와 공간 복잡도 분석
시간 복잡도
- 모든 가능한 단어 생성
- 모음 'A', 'E', 'I', 'O', 'U'를 사용하여 길이 1부터 5까지의 모든 단어를 생성하는데, 각 자리마다 5개의 선택지가 있습니다.
- 가능한 모든 단어의 수는 51+52+53+54+55=5×5−155−1=5×781=3905입니다.
- 따라서 단어 생성의 시간 복잡도는 O(3905)입니다.
- 사전순 정렬
- 생성된 3905개의 단어를 사전순으로 정렬하는데, 정렬 알고리즘의 평균 시간 복잡도는 O(n log n)입니다.
- 여기서 n은 3905이므로, 시간 복잡도는 O(3905 log 3905)입니다.
- 단어의 위치 찾기
- 정렬된 리스트에서 주어진 단어의 위치를 찾는 것은 리스트를 순회하는 과정으로, 시간 복잡도는 O(n)입니다.
- 여기서 n은 3905이므로, 시간 복잡도는 O(3905)입니다.
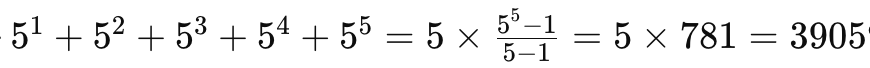
종합적으로, 시간 복잡도는 O(3905) + O(3905 log 3905) + O(3905)로, 주요 시간 복잡도는 O(3905 log 3905)입니다.
공간 복잡도
- 모든 가능한 단어 저장
- 생성된 모든 단어를 저장하는 리스트의 크기는 3905입니다.
- 각 단어의 길이는 최대 5이므로, 최악의 경우 각 단어는 5개의 문자를 저장합니다.
- 따라서, 저장 공간은 O(3905 \times 5)로, O(19525)입니다.
- 재귀 호출 스택
- 최대 재귀 깊이는 5입니다 (단어의 최대 길이).
- 각 재귀 호출에서 생성되는 임시 변수들은 상수 개수이므로, 재귀 호출 스택의 공간 복잡도는 O(5)입니다.
종합적으로, 공간 복잡도는 O(19525)입니다.
요약
- 시간 복잡도: O(3905 log 3905)
- 공간 복잡도: O(19525)
새로운 풀이... 수학적 접근...
완전탐색 방법 대신, 수학적 접근을 통해 주어진 단어의 위치를 효율적으로 계산하는 방법을 사용합니다. 이 접근 방식은 사전순으로 나열된 모든 단어에서 특정 단어의 위치를 계산한다.
- 차이점:
- 제시된 코드는 재귀 호출과 리스트를 사용하여 모든 단어를 생성하고 정렬하는 대신, 각 자리의 중요도를 이용해 단어의 위치를 직접 계산해준다.
- 이 방법은 사전순 정렬 없이 단어의 위치를 빠르게 계산하는 차이점이 있다.
- 장점:
- 시간 복잡도가 매우 낮습니다. 모든 가능한 단어를 생성하고 정렬하는 O(3905 log 3905)보다 훨씬 효율적입니다.
- 공간 복잡도도 낮습니다. 추가 리스트나 재귀 호출 스택을 사용하지 않으므로 메모리 사용이 적습니다.
- 단점:
- 직관적이지 않으며, 특정 수학적 패턴을 이해해야 합니다.
- 모든 단어를 실제로 생성하지 않으므로, 다른 용도로 단어들을 사용할 수 없습니다.
알고리즘은 수학적 패턴을 이해해야지 더 접근할 수 있다.
열심히 공부해야겠네..
'Algorithm > 코딩테스트' 카테고리의 다른 글
| [프로그래머스][JAVA] 87694. 아이템 줍기 (1) | 2024.06.09 |
|---|---|
| [프로그래머스][JAVA] 43164. 여행경로 (1) | 2024.06.09 |
| [프로그래머스][JAVA] 84021. 퍼즐조각채우기 (0) | 2024.06.01 |
| [프로그래머스][JAVA] 86971. 전력망을 둘로 나누기 (0) | 2024.06.01 |
| [프로그래머스][JAVA] 84512. 모음사전 (0) | 2024.05.28 |