Elasticsearch 색인(Index) 구조 완전 정복
1. 서론 – Elasticsearch를 이해하려면 Lucene부터
Elasticsearch는 강력한 분산 검색 엔진이지만, 그 핵심에는 Apache Lucene이라는 라이브러리가 있습니다. Elasticsearch는 데이터를 검색하기 위해 Lucene을 내부적으로 사용하며, 색인(index)과 검색(search)과 관련된 대부분의 기능은 Lucene의 구조 위에 구축되어 있습니다.
따라서 Elasticsearch의 동작 원리를 정확히 이해하려면 Lucene이 데이터를 어떻게 색인하고 검색하는지를 먼저 알아야 합니다.
2. Lucene의 색인 구조와 Elasticsearch 내부 동작
2.1 문서 색인과 Flush
문서가 색인될 때, Lucene은 해당 문서를 분석(analyze)하여 역색인(Inverted Index)을 생성합니다. 이 색인 정보는 최초에는 메모리 내 버퍼에 저장됩니다.
버퍼는 일정 주기 또는 크기가 임계치를 초과하면 디스크에 flush되며, 이때 Lucene은 메모리 데이터를 디스크상의 세그먼트(segment) 파일로 변환합니다. 이 세그먼트는 이후 검색이 가능한 단위가 됩니다.
📌 정리 :색인 요청 → 메모리 버퍼 → flush → 세그먼트(검색 가능)
2.2 Refresh – Elasticsearch만의 색인 노출 과정
Lucene은 디스크에 저장된 세그먼트를 통해서만 검색을 수행합니다. 즉, flush는 되었지만 새 세그먼트가 아직 열리지 않았다면 검색에 반영되지 않습니다.
Elasticsearch는 Lucene의 DirectoryReader를 사용해 세그먼트를 열고, 변경 사항이 생겼을 때 openIfChanged()를 호출하여 새로운 Reader를 생성합니다. 이 과정을 refresh라고 부릅니다.
✅ refresh는 Lucene 레벨의 새 세그먼트를 Elasticsearch가 감지하고 반영하는 작업입니다.
이 작업은 비용이 들기 때문에 기본적으로 1초 주기로 수행되며, 필요 시 POST /_refresh API를 통해 수동으로 실행할 수 있습니다.
2.3 Commit – 디스크에 안전하게 기록하기
Lucene의 flush는 시스템 페이지 캐시에만 데이터를 저장합니다. 이를 디스크에 영구적으로 기록하려면 commit 작업이 필요합니다. commit은 시스템 호출(fsync)을 통해 데이터를 디스크에 동기화하는 과정입니다.
Elasticsearch의 flush API는 내부적으로 이 Lucene commit을 포함합니다.
📌 주의:
Lucene의 flush는 메모리 → 파일로 데이터 이동
Lucene의 commit은 캐시 → 디스크로 동기화
Elasticsearch의 flush는 commit을 포함하며 더 무거운 작업
2.4 세그먼트 구조와 병합(Merge)
Lucene은 색인 시마다 새로운 세그먼트를 생성하며, 각 세그먼트는 불변(Immutable) 구조입니다. 문서가 삭제되거나 수정되더라도 실제로 세그먼트를 변경하지 않고, 삭제 플래그를 표시하거나 새 세그먼트를 생성합니다.
이 때문에 시간이 지남에 따라 세그먼트 수가 많아질 수 있습니다. Lucene은 성능 유지를 위해 세그먼트 병합(Merge)을 수행합니다.
- 병합 시 삭제된 문서를 정리하고, 여러 세그먼트를 하나로 압축합니다.
- 병합은 비용이 큰 작업이므로, 색인이 더 이상 발생하지 않을 때 명시적으로 수행하는 것이 좋습니다.
2.5 Lucene Index vs Elasticsearch Index
- 여러 개의 세그먼트가 모이면 하나의 Lucene 인덱스가 됩니다.
- Elasticsearch의 샤드(Shard)는 Lucene 인덱스를 래핑한 단위입니다.
- Elasticsearch는 하나의 인덱스를 여러 샤드로 분할하여 분산 저장하고, 클라이언트 요청 시 각 샤드에서 검색한 결과를 병합하여 응답합니다.
- 즉, Lucene 인덱스 : Elasticsearch 샤드 = 1:1 관계
- Elasticsearch 인덱스 : 샤드 N개 = 1:N 관계
3. Translog – 데이터 유실 방지를 위한 로그 시스템
Lucene commit 이전에 장애가 발생하면 데이터 유실 위험이 있습니다. 이를 방지하기 위해 Elasticsearch는 모든 색인/삭제 작업을 Translog(트랜잭션 로그)에 기록합니다.
- Translog는 작업 수행 직후 기록되며, 이 기록이 끝나야 클라이언트에게 성공 응답을 보냅니다.
- 장애 발생 시, 복구 과정에서 Translog를 재적용하여 데이터 정합성을 보장합니다.
- 다만 Translog가 너무 커지면 복구 시간이 증가하므로, 주기적으로 flush를 수행해 Translog를 작게 유지하는 것이 중요합니다.
4. Elasticsearch의 색인 구조 요약
| 용어 | 설명 |
|---|---|
| Document | Elasticsearch에 저장되는 JSON 데이터 단위 |
| Index | 문서들을 모은 논리적 단위. RDB의 테이블과 유사 |
| Shard | 인덱스를 분할한 단위. 샤드 하나는 Lucene 인덱스를 감싼 구조 |
| _id | 인덱스 내 문서를 고유하게 식별하는 키 |
| Type | 과거에 존재했던 논리적 분류 단위 (현재는 폐기됨) |
| Primary/Replica Shard | 데이터의 원본/복제본 역할을 하는 샤드 |
참고: Elasticsearch 6 이후로 하나의 인덱스에 하나의 타입만 허용되며, 7버전 이후 타입 관련 API는 더 이상 사용되지 않습니다.
5. 색인을 자세히 공부해야 하는 이유
Elasticsearch는 색인 기반 검색 엔진입니다. 색인을 깊이 있게 이해해야만 다음과 같은 실무적 문제들을 해결할 수 있습니다:
- 불필요한 리소스 소모 (불필요한 필드 색인)
- 검색 누락, 잘못된 결과
- 색인 재작업에 따른 운영 부담
- 검색 성능 저하
✅ 색인 관련 필수 개념 요약
| 항목 | 설명 |
|---|---|
| Mapping | 필드의 구조와 데이터 타입 정의 |
| Analyzer | 텍스트 분석기. 형태소 분리, 불용어 제거 등을 담당 |
| Tokenizer | 문자열을 토큰으로 분해 |
| Inverted Index | 단어 → 문서 매핑 구조. Elasticsearch 검색의 핵심 |
| Index Settings | 샤드 수, 복제 수, 분석기 설정 등 |
2. Elasticsearch 구조 개괄
샤드, 노드, 클러스터를 중심으로 이해하는 색인 분산 저장 구조
2.1 문서(Document), 인덱스(Index), 샤드(Shard)의 관계
| 구성 요소 | 설명 |
|---|---|
| Document | Elasticsearch가 저장하고 색인하는 데이터의 기본 단위. JSON 형식으로 표현됨 |
| Index | 관련된 문서들을 묶는 논리적 단위. RDB의 테이블에 대응됨. 클라이언트는 인덱스 단위로 검색 요청을 보냄 |
| Shard | 하나의 인덱스를 분산 저장하기 위한 물리적 단위. 인덱스는 여러 개의 샤드로 나뉘어 저장됨 |
Elasticsearch는 데이터를 대규모로 처리하기 위해 하나의 인덱스를 여러 샤드로 분리해 저장합니다. 이는 분산성과 확장성 확보를 위한 핵심 구조입니다.
2.2 Primary Shard와 Replica Shard
Elasticsearch는 고가용성을 위해 모든 primary shard의 복제본을 replica shard 형태로 유지합니다.
- Primary Shard: 실제 데이터가 저장되는 원본 샤드
- Replica Shard: Primary를 복제한 샤드. 장애 발생 시 역할을 대체할 수 있음
- Elasticsearch는 같은 종류의 샤드가 동일 노드에 존재하지 않도록 자동으로 샤드를 분산 배치합니다.
예시:
- shard-0(primary)와 shard-0(replica)는 서로 다른 노드에 존재해야 함
- shard-1(replica)와 shard-1(replica)가 같은 노드에 중복되어 배치되는 일도 없음
2.3 _id와 Type
| 요소 | 설명 |
|---|---|
| _id | 인덱스 내의 각 문서를 고유하게 식별하는 키. 인덱스 이름과 _id 조합은 클러스터 내에서 유일함 |
| Type | 과거 Elasticsearch에서 문서 그룹을 논리적으로 구분하기 위해 사용됐던 개념. 현재는 폐기됨 |
⚠️ Type은 Elasticsearch 6.x부터는 인덱스당 하나만 허용되며, 7.x 이후로는 사실상 사라졌습니다.
지금은 _doc이 기본값으로 고정되며, 문서 구분이 필요하다면 별도의 인덱스를 생성해야 합니다.
2.4 노드(Node)의 역할
Elasticsearch 클러스터를 구성하는 기본 단위가 노드(node)입니다. 하나의 Elasticsearch 프로세스가 하나의 노드를 구성하며, 각 노드는 다음과 같은 역할 중 하나 이상을 수행합니다.
| 노드 유형 | 역할 |
|---|---|
| Master Node | 클러스터 상태 관리, 노드 추가/제거, 인덱스 생성 등 메타데이터 관리 담당. 클러스터 내 1대가 선출됨 |
| Data Node | 실제 데이터를 저장하고 색인/검색 요청을 수행하는 노드. 샤드를 물리적으로 보유 |
| Coordinating Node | 클라이언트의 검색/색인 요청을 받아 다른 노드로 요청을 분배하고 결과를 취합해 응답 반환 |
| Ingest Node | 색인 전에 문서를 전처리하는 역할 (파이프라인 기능) |
하나의 노드는 여러 역할을 동시에 수행할 수도 있고, 역할별로 분리된 전용 노드를 구성할 수도 있습니다.
2.5 클러스터(Cluster)
Elasticsearch 클러스터는 하나 이상의 노드로 구성됩니다. 모든 노드는 동일한 클러스터 이름을 공유하며, 서로 통신하면서 클러스터 전체의 상태를 유지합니다.
- 클러스터의 핵심 특징
- 노드가 동적으로 추가/제거될 수 있음
- 자동으로 샤드를 재분배하여 데이터 일관성과 고가용성 유지
- 각 노드는 클러스터 전체에 대한 정보를 알고 있음 (Gossip 프로토콜 기반)
🧩 구조 요약 이미지
[ Elasticsearch Cluster ]
┌────────────┐ ┌────────────┐ ┌────────────┐
│ Node 0 │ │ Node 1 │ │ Node 2 │
│ (Primary) │ │ (Replica) │ │ (Primary) │
│ Shard 0 │ │ Shard 0 │ │ Shard 1 │
│ Shard 1 │ │ Shard 1 │ │ Shard 2 │
└────────────┘ └────────────┘ └────────────┘
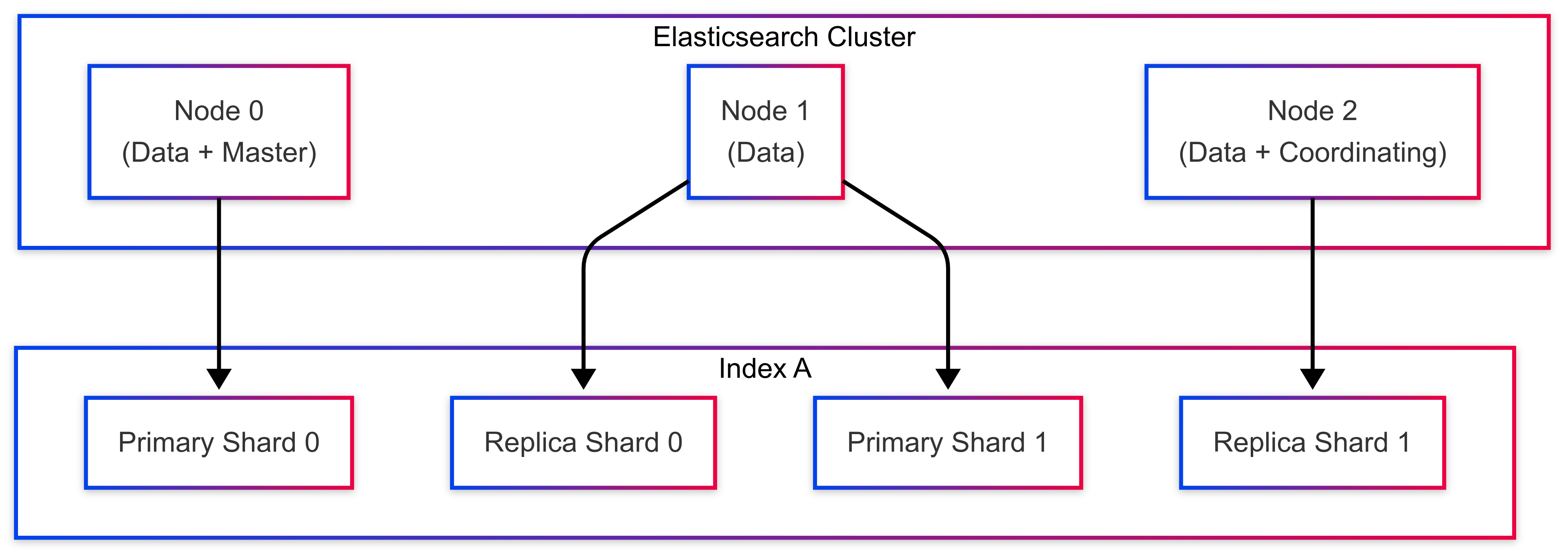
💡 설명
- Node 0, Node 1, Node 2는 각각 Elasticsearch 노드를 나타냅니다.
- Primary Shard, Replica Shard는 인덱스 A의 분산 저장 구조를 표현합니다.
- Shard0_Primary, Shard1_Primary는 서로 다른 노드에 위치하며, 각각 복제 샤드(Replica)도 다른 노드에 분산되어 있습니다.
- Elasticsearch는 고성능 검색을 위해 분산 구조를 채택하고 있으며, 이 구조의 핵심은 인덱스 → 샤드 → 노드로 이어지는 계층적 설계입니다.
- 노드들은 역할에 따라 기능을 분담하고, 클러스터 전체는 자율적으로 샤드를 관리하며 확장성과 고가용성을 보장합니다.
- 실무에서 Elasticsearch를 안정적으로 운영하려면 이 구조를 정확히 이해하고 있어야, 장애 대응이나 성능 최적화에 효과적으로 대처할 수 있습니다.
Elasticsearch에서 색인은 단순한 데이터 저장이 아닌, 검색 성능, 정확성, 운영 효율성 전반에 영향을 미치는 핵심 요소입니다.
Lucene의 구조를 기반으로, Elasticsearch가 색인을 어떻게 관리하고, 검색에 어떻게 반영하는지를 정확히 이해하면 실무에서 훨씬 강력하고 안정적인 검색 시스템을 구축할 수 있습니다.
'데이터베이스 > Elasticsearch' 카테고리의 다른 글
| Elasticsearch 아키텍처 구성 요소 (0) | 2025.03.25 |
|---|---|
| Elasticsearch란? Elasticsearch 입문자를 위한 이해하기 쉬우면서도 전문적인 지식을 알아보자. (0) | 2025.03.25 |